Supongamos que trabajamos en una fábrica de mangueras y que para poder competir en el mercado internacional es necesario que las mangueras satisfagan ciertas características técnicas. Si las pruebas a que debemos someter las mangueras son tan rigurosas y exigentes que al probar las mangueras estas se echan a perder, ¿cómo podemos garantizar a nuestros clientes la calidad de nuestro producto? Es claro que si decidimos probar toda la producción conoceríamos con exactitud la calidad de las mangueras, pero no tendríamos productos para vender. Una alternativa razonable consiste en probar tan sólo algunas de las mangueras, de tal forma que el costo del estudio de calidad no sea excesivo, pero que a la vez podamos saber que si el resto de la producción tiene la misma calidad, nuestro producto satisface o no satisface las características técnicas requeridas.
Los resultados técnicos que obtendríamos al someter algunas mangueras a estas pruebas rigurosas nos permiten determinar con certeza las características técnicas de sólo una parte del total de mangueras. Es conveniente entonces tener claro si los datos que estamos analizando corresponden al total de las observaciones, que es llamado la población, o a una parte de ellas, llamada muestra. Existen muchas situaciones donde la recopilación y el análisis de los datos se efectúan sobre una muestra y no sobre toda la población. Un ejemplo común donde los datos que obtenemos corresponden a unas muestras son las encuestas de intención de voto antes de una elección, donde sería muy costoso preguntar a cada uno de los electores por qué partido o candidato piensa votar. De hecho, en este caso no es posible conocer con precisión la población, que consiste de aquellos ciudadanos que efectivamente ejercen su voto el día de la elección.
Debido a que es muy importante distinguir en un problema estadístico si los datos corresponden a una muestra o a la población completa, veamos otro par de ejemplos que ilustren esta diferencia.
1.-Un laboratorio médico prueba un analgésico en 100 pacientes que sufren de migrañas. La muestra en este caso consiste de los 100 pacientes sometidos al tratamiento, mientras que la población estará constituida por todas aquellas personas que padezcan de migrañas y se sometan al mismo tratamiento con este analgésico.
2.-Una empresa de publicidad conoce los costos de producción de ocho comerciales para televisión. ¿Se trata de una muestra o de la población? La respuesta depende del uso que hagamos con estos datos. Si los datos los empleará el contador de la empresa para determinar el pago de los impuestos correspondientes a los ingresos por los ocho comerciales, entonces se trata de la población. Si los costos de estos comerciales se emplearán para estimar costos de comerciales que se hagan a futuro, entonces se trata de una muestra.
Cuando afirmamos que los sonorenses son más altos que los veracruzanos nos encontramos con que habrá sonorenses más altos que algunos veracruzanos pero también hay veracruzanos más altos que algunos sonorenses ¿Entonces tiene sentido una afirmación de este tipo?
Existe una medida que asociamos a un conjunto de datos y nos permite responder a las preguntas arriba planteadas, que es la media. La media de un conjunto de datos es lo que comúnmente llamamos el promedio, pero como la palabra promedio tiene otros significados, los estadísticos prefieren emplear la palabra media. La media de n números es simplemente su suma dividida por n.
En el caso de las califcaciones del examen de física la media es
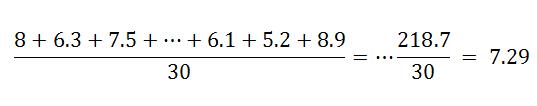

x
(que leemos "equis barra") para designar a la media de una muestra, y si además utilizamos el símbolo ∑ para describir la suma de una serie de datos, la expresión anterior queda así.

La media de una población se define de la misma manera, pero se emplean símbolos diferentes: la letra griega μ (mu) para la media de la población y N para el tamaño de la población, de modo que

¿Son efectivamente más altos los sonorenses que los veracruzanos? Una manera de responder a esta pregunra consistiría en calcular la media de la altura de los sonorenses y después la media de las alturas de los veracruzanos y comparar estas medias.
La media es sin duda la medida de mayor uso para representar el medio o el centro de un conjunto de datos. Akgunas de las propiedades de la media son las siguientes:
1.-Puede ser siempre calculada para cualquier conjunto de datos numéricos.
2.-Cualquier conjunto de datos numéricos tienen una y sólo una media.
3.-Puede ser empleada para un análisis estadístico posterior, como por ejemplo, las medios de vrios conjutos de datos pueden ser (según sea el caso) combinadas para obtener la media de todos los datos.
4.-Es una muestra confiable en el sentido de que las medias de varias muestras de una población generalmente no difieren mucho.
5.-La media es sensible a valores extremos.
Para ilustrar la úlima propiedad de la media, la sensibilidad a los valores extremos, consideremos las edades a las que murieron los miembros de dos familias. Digamos que cada una de estas familias tiene nueve miembros y las edades a las que murieron son :


Para evitar que algunos valores muy pequeños o muy grandes alteren el "centro " o la "mitad" de un conjunto de datos en ocasiones es preferible emplear otras medidas diferentes de la media. Una de estas medidas es la mediana, que se obtiene ordenando los datos y escogiendo el valor que está en medio, o la media de los dos valores centrales.

y en ambos casos 74 constituye la mediana de los años de vida de ambas familias.

y en ambos casos 74 constituye la mediana de los años de vida de ambas familias.
Veamos ahora un ejemplo con un número par de datos. Si durante los diez partidos de un torneo de futbol un equipo anotó 3,2,0,3,2,1,1,4,7 y 3 goles ¿cuál es la mediana? Al ordenar los valores se tiene
0 1 1 2 2 3 3 3 4 7
y los valores centrales son 2 y 3, que ocupan los lugares 5 y 6 de la lista de 10 valores.
La mediana es entonces (2+3)/2 =2.5

cuando n es par el conjunto de datos con valores menores a la mediana constituye el 50% de los datos, mientras que el conjunto de datos con valores mayores a la mediana constituye el otro 50%
y cuando n es impar el conjunto de datos con valores menores o iguales a la mediana constituirá el 50% y los datos con valores mayores el otro 50% o bien puede también ser que el conjunto de datos con valores menores a la mediana constituirá el 50% y los datos con valores iguales o mayores
a la mediana constituirán el otro 50%.
Cuando analizamos grandes cantidades de datos en ocasiones resulta también interesante conocer el valor de los datos que determinan el primer 25 % de los datos y el 75% de los datos . A estos valores se les conoce como el cuartil inferior y el cuartil superior. Si se tienen d datos, entonces el cuartil inferior es el valor del dato correspondiente al entero más cercano a n/4 y el cuartil superior es el valor del dato correspondiente al entero más cercano a 3n/4. Por ejemplo, si se tienen 739 datos, 739/4 =184.75, y el cuartil inferior estará dado por el valor del dato 185, mientras que el cuartil superior es el dato 554, ya que (3 x 739)/4 = 554.25. En el caso en que en alguna de las fracciones n/4 o 3n /4 esté a la mitad entre dos números enteros, podemos tomar la media de estos datos como el correspondiente cuartil.
Por ejemplo, para calcular la mediana del examen de física debemos primero escribir las 30 calificaciones por orden ascendente; 3.9, 4.6 ,4.8, 5.2 ,5.5 ,5.8 ,5.9 ,6.1 ,6.3 ,6.6, 6.7 ,6.9,7.4, 7.4, 7.5 ,7.5, 7.6,7.8,7.9 , 8 ,8.1 8.3 ,8.5 ,8.8, 8.9 ,8.9 ,9 ,9.2 9.6,10. Los lugares 15 y 16 corresponden a kas calificaciones 7.5 y 7.5 , por lo que la mediana es 7.5. Como 30/4 = 7.5, para obtener el cuartil inferior calculamos la media de los datos 7 y 8: (5.9+6.1)/2 =6 . El último cuartil es la media de los datos 22 y 23: (8.3+8.5)/2 = 8.4. Sabemos entonces que la mitas de las calificaciones fueron inferiores o iguales a 7.5 y la otra mitad superiores o iguales a 7.5, y que además el 25% más bajo de las calificaciones fue superior o igual a 8.4.
Otra medida que se usa a veces para describir la "mitad " o la tendencia central de un conjunto de datos es la moda. Se define simplemente como el valor del dato que aparece con más frecuencia .
La moda también se puede definir para distribuciones de frecuencia categóricas donde tomamos como la moda a la clase que agrupa más datos. Supongamos, por ejemplo, que al realizar una encuesta para estudiar las preferencias de aficionados a siete equipos de futbol en México se obtuvieron los resultados de la siguiente grafica barras. Ahí es facil apreciar que la barra más alta corresponde al Guadalajara con 960 seguidores, por lo que la moda (o decisión modal)es el Guadalajara.

Cuando buscamos promediar cantidades, a veces nos enfrentamos al hecho de que no todos los datos tienen la misma importancia o el mismo peso. Consideremos el caso de una empresa mensajeria que cuenta con 32 vehículos para repartir paquetes. La siguiente tabla muestra cuántas unidades hay de cada tipo y cuál es su rendimiento por litro de gasolina

¿Cómo calcúlamos el rendimiento promedio que dan todos los vehiculos repartidores de la empresa?Es claro que si calculamos la media de los rendimientos, obtendríamos el rendimiento promedio como si la empresa contase con un auto de cada tipo, mientras que en este caso debemos de otorgar mayor peso a los Volswagen Sedán y a los Tsurus que son los más numerosos y menos peso a los Pick-up Nissan que únicamente son tres. Una manera natural consiste en contar cada rendimiento tantas veces como unidades del tipo haya, de modo que el rendimiento total será

Recordemos que cuando se tiene una expresión como la de arriba, efectuamos primero las operaciones dentro de los parentesis del númerador , después las sumas, y una vez hemos calculado el numerador procedemos a dividir.
Veamos otro ejemplo semejante. Una cooperativa de pescadores capturó en una semana 1.5 toneladas de camarón, 3.4 toneladas de sierra, 2.9 toneladas de atún, 3.8 toneladas de bandera y 0.8 toneladas de dorado. Los precios a kis que se comercializó la pesca fueron $ 20 000.00 por tonelada de camarón, $ 6000.00 por tonelada de sierram $ 12 000 por tonelada de atún, $ 8 000.00 por tonelada de bandera y $ 14 000 por tonelada de dorado. ¿Cuál fue el precio promedio que recibieron por tonelada? De nuevo , lo más conveniente será multiplicar el precio de cada producto por la cantidad vendida durante la semana para obtener el ingreso total, y después dividir por el total de toneladas pescadas:

Así, el precio promedio por tonelada fue de $ 10 225.80 .
En general para poder promediar estas cantidades que no tienen la misma importancia es necesario asignar a cada una un peso. Si los datos x1, x2, x3,... ,xn ,tienen pesos w1, w2, w3,... ,wn
su media ponderada está dada por

En general, la información contenida en los datos nos indica queé pesos debemos utilizar en la media ponderada. Un caso que se presenta con frecuencia es cuando las cantidades que queremos promediar difieren porcentualmente.
Consideremos, por ejemplo, a Doña Gamucita Pilongano que al enviudar invirtió el 35% del seguro de vida de su marido en acciones de Telmex, el 25% en acciones de Cemex y el 40% restante en Cetes.Si en cierto periodo las acciones de Telmex rindieron un beneficio de 4.5 %, las de Cemex el 3.6% y los Cetes el 3.9%, ¿cuál es el beneficio promedio que obtuvo doña gamucita en este periodo?Los pesos corresponden ahora a la distribución porcentual de la inversión de doña Gamucita, 35,25 y 40 que suman obviamente 100, así que el rendimiento promedio de la inversión fue de
 .
.
No hay comentarios:
Publicar un comentario