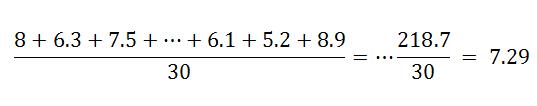En este post buscaremos complementar la información importante que brindan las medidas de tendencia central acerca de un conjunto de datos. Supongamos que tenemos dos pacientes sometidos a un tratamiento para regularizar su presión arterial en un hospital. La enfermera entrega al médico los siguientes reportes de su presión sistólica (máxima) durante las últimas 24 horas

La media en ambos casos es de 117 Mg Hg, que es aceptable para la edad de los pacientes. Sin embargo, el médico difícilmente encontrará satisfactorio el tratamiento del paciente B. ¿Por qué? Es claro que la forma en que se distribuyen las presiones arteriales de los dos pacientes es muy diferente, ya que en el primer caso la variabilidad es muy pequeña, mientras que en el segundo es muy alta.
Un aspecto que salta a la vista es la diferencia de rangos en el ejemplo anterior. El rango o amplitud de un conjunto de datos numéricos es simplemente la diferencia entre el dato mayor y el menor. Para el paciente A el rango está dado por 124-110= 14, y para el paciente B obtenemos el rango mucho más amplio, pues 157-79=78.El rango es una medida que se entiende y calcula fácilmente, pero no es muy útil como medida de dispersión. Para ilustrar esto consideremos los siguientes conjuntos de datos.

Consideremos una población con datos x1 , x2, x3,…, xN.Si la media de la población es μ, entonces las diferencias x1 - μ, x2 - μ, x3 - μ,…, xN - μ, son las desviaciones de la media. ¿Es razonable tomar a la media de estas desviaciones como medida de variabilidad? Aunque a primera vista parece correcto, observemos que como la media se encuentra aproximadamente al centro de los datos, estas diferencias serán positivas para aquellos datos xi que sean mayores a la media y negativos para aquellos que sean menores, de modo que al sumar las desviaciones de la media habrá muchas cancelaciones. De hecho, no es difícil comprobar que la suma de las desviaciones de la media, y en consecuencia su media, es siempre cero.
Sin embargo, si elevamos al cuadrado las diferencias de las medias, éstas serán siempre positivas, a excepción del caso de que el dato xi coincida con la media, esto es cuando xi - μ es cero. Si tomamos la media de estos cuadrados y sacamos su raíz cuadrada (para compensar que las desviaciones fueron elevadas al cuadrado) obtenemos la desviación estándar de la población que se denota por la letra griega σ (sigma).

x
por μ y n por N, pero no es así. En lugar de dividir por n, el tamaño de la muestra se divide por n-1.
Para calcular la desviación estándar debemos (1) determinar la media
x
, (2) las diferencias de las medias, (3) elevar al cuadrado estas diferencias, (4) sumar los cuadrados, (5) dividir por n-1, y finalmente (6)sacar la raíz cuadrada. Calculemos la desviación estándar de las presiones de los pacientes .Debemos primero decidir cuál de las dos expresiones usar, es decir, si se trata de muestras o de poblaciones. Es claro que las lecturas que tenemos de los pacientes corresponden a un pequeño registro de sólo seis reportes que tomó la enfermera. Si el médico lo hubiese indicado se podría haber llevado un registro más frecuente de las presiones de los pacientes. Por tanto corresponde a la expresión para una muestra.



El procedimiento arriba señalado para calcular desviaciones estándar puede abreviarse un poco.
El procedimiento arriba señalado para calcular desviaciones estándar puede abreviarse un poco.Observemos que

Entonces,
 Y por lo tanto, la desviación estándar de la media también la podemos obtener por la siguiente expresión
Y por lo tanto, la desviación estándar de la media también la podemos obtener por la siguiente expresión

x.
Para ilustrar el empleo de esta nueva expresión calcularemos de nuevo las desviaciones estándar de las presiones de los pacientes A y B. 
La desviación estándar de la muestra de las presiones del paciente A es


La importancia de la desviación estándar no sólo radica en el hecho de que nos da información de cómo se distribuyen los datos de un conjunto alrededor de su media, sino que además es muy útil en problemas de inferencia que trataremos más adelante.
Y la del paciente B es

Y la del paciente B es

El siguiente resultado, conocido como el teorema de Chebishev, en honor del matemático ruso Pafnuti Shevishev (1821-1894), nos indica con mayor precisión cómo la desviación estándar refleja la manera en que los datos de distribuyen alrededor de la media .

Veamos cómo podemos aplicar este resultado a las calificaciones del examen de física que estudiamos en un post anterior. Para calcular la desviación estándar calcularemos usaremos la expresión

,ya que se trata ahora de todas las calificaciones del examen, es decir, la poclación. En este caso N=30,
(∑x) 2, =(3.9+4.6+…+10)2, =(218.7)2, =47829.69 ,∑x2, = (3.9) 2, + (4.6)2, +…+(10)2, =1665.55.
Por lo tanto,

La media de este conjunto de calificaciones es de 7.29. El teorema de Chevishev asegura que, por ejemplo, para k=1.5, entonces 1-1/1.5 =0.552, por lo que cuando menos el 55% de las califciaones son mayores a 7.29- (1.5)(1.54)= 4.98 y son menores que 7.29 + (1.5)(1.54)=9.6.
Es muy útil que el valor de la constante k del teorema de Chevishev sea arbitrario. Consideremos por ejemplo una empresa papelera que vende paquetes de hojas para fotocopiado. Los paquetes tienen una media de 500 hojas con una desviación estándar de 0.6. ¿Cuál es el mínimo porcentaje de paquetes que contienen entre 498 y 502 hojas? En este caso estamos permitiendo que haya una variación de 2 hojas por paquete. Al expresar esta variación en términos de desviaciones estándar tenemos la ecuación 2= .6k, y al resolverla tenemos que k= 3.33. Como 1- 1/3.332=0.91, el teorema de Chevishev nos gaantiza entonces que cuando menos el 91]% de los paquetes contiene entre 498 y 502 hojas.
El teorema de Chevishev se aplica a cualquier conjunto de datos y nos dice que cuando menos un porcentaje de ellos se encuentra entre ciertos límites. En el caso del ejemplo anterior sabemos que al menos 91% de los paquetes contiene entre 498 y 502 hojas , pero podría haber un porcentaje mayor dentro de estos límites.
En el caso del examen de física sabemos que al menos 55 % de las calificaciones están entre 4.98 y 9.6 y, de hecho, este porcentaje es mucho mayor, ya que únicamente 4 calificaciones no caen en este rango, lo que equivale al 13.33 %. Más adelante estudiaremos distribuciones muy comunes de forma de campana donde se tiene mucha más información sobre la variabilidad de datos.
Ya hemos determinado fórmulas para obtener la media y desviación estándar de un conjunto de datos. ¿Es posible determinar la media, la mediana y la desviación estándar cuando los datos que tenemos ya vienen agrupados? Esto sucede con mucha frecuencia en los datos que se publican por el INEGI o por algún otro organismo o empresa.
Ya mencionamos que al agrupar datos se pierde información y por lo tanto debemos conformarnos con una aproximación de la media, mediana y desviación estándar. Para calcular estos parámetros se asigna a cada dato el valor de su marca de clase correspondiente. Así, si se tienen k clases y si denotamos por xi al valor de las marcas de clase i y por fi a su frecuencia, entonces debemos contabilizar f1 veces a x1, f2 veces a x2, etc. Entonces el total de datos es n= f1 + f2 +…+ fk y la media de una muestra está dada entonces por


Veamos cómo aplicar estas fórmulas para obtener la media y la desviación estándar a partir de datos agrupados por el histograma de las calificaciones del examen de física que revisamos en un post anterior.

La siguiente tabla contiene los cálculos necesarios para poder aplicar las fórmulas de arriba. Veamos cómo obtuvimos los datos del tercer renglón. El tercer renglón corresponde a los exámenes que obtuvieron calificación 6, que es precisamente el valor de la marca de clase x. En la segunda columna aparece x2 = 62, =36, en la tercer columa la frecuencia f=5 , que es el número de alumnos que obtuvieron calificación 6, en la cuarta y quinta columna aparecen los productos x ∙f = 6∙5=30 y x2, ∙f=36 ∙5 =180.Los otros renglones se calculan de la misma manera.


Y la desviación estándar es

Una vez que han sido agrupados los datos tampoco es posible determinar el valor exacto de la mediana. Sabemos que, después de ordenar los datos, la mediana es el valor del dato que divide en dos conjuntos de igual tamaño a todos los datos. Cuando los intervalos de clases son iguales, la mediana se puede determinar como el número que divide el área total del histograma en dos partes iguales, una a la izquierda y otra a la derecha.
En el histograma del examen de física las bases de los rectángulos son siempre iguales a 1 , aspi que el área total de los rectángulos es de 30. La suma de las áreas de los primeros cuatro rectángulos es de 15, de modo que la mediana es el valor divisorio de esta clase, que es de 7.5. Este valor coincide en este caso con el valor real de la mediana antes de agrupar los datos. Analicemos ahora un ejemplo un poco más elaborado desde el punto de vista computacional, es decir, donde el número de operaciones y la magnitud de los números es mucho mayor.
Consideremos de nuevo los matrimonios en México durante 1995. En la tabla de los matrimonios apreciamos dos clases abiertas, la clase de los matrimonios donde la contrayente tiene menos de 15 años y la clase donde la contrayente tiene más de 50 maños. Ambas clases son pequeñas en relación con el total de matrimonios, pues cada una contiene menos del 1.5% . Para clases abiertas no tenemos una forma precisa de determinar sus marcas de clase y esto dificulta los cálculos. En este cosa, con la información que contamos, trataremos de asignar de manera razonable una marca de clase para cada una de estas dos clases. Para la primera es más sencillo, puesto que la mayoría de las contrayentes menores de 15 años deben de contar con 14 años, asignando a esta clase la marca 14. Para la última clase la situación es más complicada. Ya que el número de matrimonios baja considerablemente al aumentar la edad de la contrayente, podemos suponer que esta situación se repite dentro de la última clase, es decir, que hubo más contrayentes cercanas a los 50 años que arriba de 70 años.
Así, de manera un poco arbitraria asignemos 60 como marca de la última clase. Ya habíamos observado que los valores divisorios a partir de la segunda clase son 15, 20,25,,,etc.
Las marcas de clase son entonces (15+20)/2 =17.5, (20+25)/2=22.5, etc.

En la siguiente tabla se han calculado los valores de x∙f y de x2 ∙f. Por ejemplo, para el primer vrenglón la clase de marca es x = 14, x2 = 142 = 196, la frecuencia es f = 9136, x ∙f =(14) (9136) y x2 ∙f = (196) (9136)= 1 790 656 .Los otro srenglones se obtienen de manera totalmente análoga.

La media en entonces

que corresponde a la edad promedio de una contrayente durante 1995. La desviación estándar es

Para calcular la mediana debemos localizar la edad de la contrayente 658114/2 =329057. Sabemos que 9136+213773=222909 matrimonios donde la contrayente cuenta con 19 años o menos y que hay 222 909 +245 537 = 468 446 matrimonios donde la contrayente cuenta con 24 años o menos. Se tiene entonces que la mediana se localiza en la tercera clase, de 20 a 24 años cumplidos. El valor divisorio inferior de esta clase es 20, el intervalo de la clase es 5 y la frecuencia de la clase es 245 537. El número de datos faltantes dentro de la clase para alcanzar la mediana es la diferencia de la mitad total de los datos menos los datos acumulados hasta la clase anterior, esto es , 329 057-222 909= 106 148 . La proporción de matrimonios de la tercera clase antes de la mediana es entonces de 106148/245537=0.433. Por lo tanto la mediana es
20+5∙ 0.433 =22.165.
En general, si el valor divisorio inferior de la clase de la mediana es L, el intervalo de la clase es c, la frecuencia de la clase es f y el número de datos faltantes dentro de la clase de la mediana r, la mediana viene dada por

Como 22.165 años es aproximadamente 22 años y dos meses, sabemos entonces que en la mitad de los matrimonios en México durante 1995 la contrayente tenía menos de 22 años y dos meses, y en la otra mitad la contrayente era mayor.
Para calcular los cuartiles podemos también utilizar la expresión de arriba, sólo que ahora hay que determinar dónde se tiene el 25% y el 75% de los datos. Debemos entonces estimar la edad de las 658114/4 =164528.5 y 3(658114/4) = 493585.5 contrayentes más jóvenes. Como sólo se trata de una aproximación no es necesario considerar números enteros o la media de los números enteros anterior y posterior.
Calculemos primero el cuartil inferior. Las dos primeras clases contienen 9136 +213773= 222909datos. Como 9136 <164528.5<222909 sabemos que el cuartil inferior se localiza en la segunda clase. La segunda clase contiene 164528.5-9136 = 153392.5 datos antes del cuartil inferior, así que el cuartil inferior está dado por

Observemos que para este caso el valor divisorio de la segunda clase es L= 15 y el intervalo vuelce a ser c=5.
El cálculo del cuartil superior es totalmente análogo. Las tres primeras clases contienen 468446 datos y las cuatro primeras clases contienen 579209 datos, por lo que el dato 493585.5 está en la clase de los matrimonios de 25 a 29 años de edad de la contrayente. Los datos faltantes son ahora 493585.5-468446=25139.5 . Aplicando la fórmula otra vez obtenemos que el cuartil superior es

Los cuartiles son 18.635 y 26.135, que equivalen aproximadamente a 18 años 7 meses y a 26 años 2 meses. Esto significa que en un cuarto de los matrimonios de México en 1995 las contrayentes tenían menos de 18 años 7 meses y que los matrimonios con contrayentes mayores de 26 años 2 meses corresponden a la cuarta parte del total de matrimonios.
Ya observamos que cuando los intervalos de las clases son iguales, se puede obtener la mediana dividiendo el histograma en dos partes con áreas iguales. La base de los rectángulos es igual a 5, a excepción de la primera y la última clase que son abiertas. Para determinar la mediana en este caso debemos eliminar estas dos clases abiertas. El efecto de eliminar estas dos clases en la localización de la mediana es muy pequeño, ya que por un lado son pequeñas, y por otro, al ser semejantes en magnitud estamos eliminado aproximadamente el mismo número de matrimonios en el extremo izquierdo que en el extremo derecho. El siguiente histograma es relevante para determinar la mediana.

Matrimonios en 1995 por edad de la contrayente
Como todos los rectángulos tienen base 5, el área total de los rectángulos es igual a 5 veces el total de matrimonios con contrayente entre los 15 y 49 años cumplidos que es de 5 ∙ 639566 =3197830. La mitad del área es de 1598915. El primer rectángulo tiene área 5 ∙ 213773=1068865 y el área del segundo es de 5 x 245 537 = 1227685. Como el área de los dos primeros rectángulos sobrepasa la mitad del área total, la mediana se encuentra en la segunda clase. ¿Qué tanto le falta al área del primer rectángulo para alcanzar la mitad del área total? Esta área faltante es de 1598915-1068865=530050. La proporción del segundo rectángulo que constituye el área faltante es igual a

Por lo que el valor de la mediana es igual al valor divisorio inferior de la segunda clase más 0.432 veces el intervalo de la clase, esto es, 20 + (0.432)(5)=22.16 años, que ya observamos equivale a un poco menos de 22 años y dos meses.

Las dificultades que tuvimos con las clases abiertas para aproximar la media y la mediana ilustran la razón de que preferentemente estas clases tengan frecuencias pequeñas en relación con el resto de las clases.